Gemini - Google AI Studio
| Property | Details |
|---|---|
| Description | Google AI Studio is a fully-managed AI development platform for building and using generative AI. |
| Provider Route on LiteLLM | gemini/ |
| Provider Doc | Google AI Studio ↗ |
| API Endpoint for Provider | https://generativelanguage.googleapis.com |
| Supported OpenAI Endpoints | /chat/completions, /embeddings, /completions |
| Pass-through Endpoint | Supported |
API Keys
import os
os.environ["GEMINI_API_KEY"] = "your-api-key"
Sample Usage
from litellm import completion
import os
os.environ['GEMINI_API_KEY'] = ""
response = completion(
model="gemini/gemini-pro",
messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}]
)
Supported OpenAI Params
- temperature
- top_p
- max_tokens
- max_completion_tokens
- stream
- tools
- tool_choice
- functions
- response_format
- n
- stop
- logprobs
- frequency_penalty
- modalities
- reasoning_content
Anthropic Params
- thinking (used to set max budget tokens across anthropic/gemini models)
Usage - Thinking / reasoning_content
LiteLLM translates OpenAI's reasoning_effort to Gemini's thinking parameter. Code
Mapping
| reasoning_effort | thinking |
|---|---|
| "low" | "budget_tokens": 1024 |
| "medium" | "budget_tokens": 2048 |
| "high" | "budget_tokens": 4096 |
- SDK
- PROXY
from litellm import completion
resp = completion(
model="gemini/gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "What is the capital of France?"}],
reasoning_effort="low",
)
- Setup config.yaml
- model_name: gemini-2.5-flash
litellm_params:
model: gemini/gemini-2.5-flash-preview-04-17
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Test it!
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-2.5-flash",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"reasoning_effort": "low"
}'
Expected Response
ModelResponse(
id='chatcmpl-c542d76d-f675-4e87-8e5f-05855f5d0f5e',
created=1740470510,
model='claude-3-7-sonnet-20250219',
object='chat.completion',
system_fingerprint=None,
choices=[
Choices(
finish_reason='stop',
index=0,
message=Message(
content="The capital of France is Paris.",
role='assistant',
tool_calls=None,
function_call=None,
reasoning_content='The capital of France is Paris. This is a very straightforward factual question.'
),
)
],
usage=Usage(
completion_tokens=68,
prompt_tokens=42,
total_tokens=110,
completion_tokens_details=None,
prompt_tokens_details=PromptTokensDetailsWrapper(
audio_tokens=None,
cached_tokens=0,
text_tokens=None,
image_tokens=None
),
cache_creation_input_tokens=0,
cache_read_input_tokens=0
)
)
Pass thinking to Gemini models
You can also pass the thinking parameter to Gemini models.
This is translated to Gemini's thinkingConfig parameter.
- SDK
- PROXY
response = litellm.completion(
model="gemini/gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "What is the capital of France?"}],
thinking={"type": "enabled", "budget_tokens": 1024},
)
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LITELLM_KEY" \
-d '{
"model": "gemini/gemini-2.5-flash-preview-04-17",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"thinking": {"type": "enabled", "budget_tokens": 1024}
}'
Passing Gemini Specific Params
Response schema
LiteLLM supports sending response_schema as a param for Gemini-1.5-Pro on Google AI Studio.
Response Schema
- SDK
- PROXY
from litellm import completion
import json
import os
os.environ['GEMINI_API_KEY'] = ""
messages = [
{
"role": "user",
"content": "List 5 popular cookie recipes."
}
]
response_schema = {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
}
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
response_format={"type": "json_object", "response_schema": response_schema} # 👈 KEY CHANGE
)
print(json.loads(completion.choices[0].message.content))
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
}}
}
'
Validate Schema
To validate the response_schema, set enforce_validation: true.
- SDK
- PROXY
from litellm import completion, JSONSchemaValidationError
try:
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
response_format={
"type": "json_object",
"response_schema": response_schema,
"enforce_validation": true # 👈 KEY CHANGE
}
)
except JSONSchemaValidationError as e:
print("Raw Response: {}".format(e.raw_response))
raise e
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
},
"enforce_validation": true
}
}
'
LiteLLM will validate the response against the schema, and raise a JSONSchemaValidationError if the response does not match the schema.
JSONSchemaValidationError inherits from openai.APIError
Access the raw response with e.raw_response
GenerationConfig Params
To pass additional GenerationConfig params - e.g. topK, just pass it in the request body of the call, and LiteLLM will pass it straight through as a key-value pair in the request body.
See Gemini GenerationConfigParams
- SDK
- PROXY
from litellm import completion
import json
import os
os.environ['GEMINI_API_KEY'] = ""
messages = [
{
"role": "user",
"content": "List 5 popular cookie recipes."
}
]
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
topK=1 # 👈 KEY CHANGE
)
print(json.loads(completion.choices[0].message.content))
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"topK": 1 # 👈 KEY CHANGE
}
'
Validate Schema
To validate the response_schema, set enforce_validation: true.
- SDK
- PROXY
from litellm import completion, JSONSchemaValidationError
try:
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
response_format={
"type": "json_object",
"response_schema": response_schema,
"enforce_validation": true # 👈 KEY CHANGE
}
)
except JSONSchemaValidationError as e:
print("Raw Response: {}".format(e.raw_response))
raise e
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
},
"enforce_validation": true
}
}
'
Specifying Safety Settings
In certain use-cases you may need to make calls to the models and pass safety settings different from the defaults. To do so, simple pass the safety_settings argument to completion or acompletion. For example:
response = completion(
model="gemini/gemini-pro",
messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}],
safety_settings=[
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
]
)
Tool Calling
from litellm import completion
import os
# set env
os.environ["GEMINI_API_KEY"] = ".."
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
messages = [{"role": "user", "content": "What's the weather like in Boston today?"}]
response = completion(
model="gemini/gemini-1.5-flash",
messages=messages,
tools=tools,
)
# Add any assertions, here to check response args
print(response)
assert isinstance(response.choices[0].message.tool_calls[0].function.name, str)
assert isinstance(
response.choices[0].message.tool_calls[0].function.arguments, str
)
Google Search Tool
- SDK
- PROXY
from litellm import completion
import os
os.environ["GEMINI_API_KEY"] = ".."
tools = [{"googleSearch": {}}] # 👈 ADD GOOGLE SEARCH
response = completion(
model="gemini/gemini-2.0-flash",
messages=[{"role": "user", "content": "What is the weather in San Francisco?"}],
tools=tools,
)
print(response)
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-2.0-flash",
"messages": [{"role": "user", "content": "What is the weather in San Francisco?"}],
"tools": [{"googleSearch": {}}]
}
'
Google Search Retrieval
- SDK
- PROXY
from litellm import completion
import os
os.environ["GEMINI_API_KEY"] = ".."
tools = [{"googleSearch": {}}] # 👈 ADD GOOGLE SEARCH
response = completion(
model="gemini/gemini-2.0-flash",
messages=[{"role": "user", "content": "What is the weather in San Francisco?"}],
tools=tools,
)
print(response)
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-2.0-flash",
"messages": [{"role": "user", "content": "What is the weather in San Francisco?"}],
"tools": [{"googleSearch": {}}]
}
'
Code Execution Tool
- SDK
- PROXY
from litellm import completion
import os
os.environ["GEMINI_API_KEY"] = ".."
tools = [{"codeExecution": {}}] # 👈 ADD GOOGLE SEARCH
response = completion(
model="gemini/gemini-2.0-flash",
messages=[{"role": "user", "content": "What is the weather in San Francisco?"}],
tools=tools,
)
print(response)
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash
litellm_params:
model: gemini/gemini-2.0-flash
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-2.0-flash",
"messages": [{"role": "user", "content": "What is the weather in San Francisco?"}],
"tools": [{"codeExecution": {}}]
}
'
JSON Mode
- SDK
- PROXY
from litellm import completion
import json
import os
os.environ['GEMINI_API_KEY'] = ""
messages = [
{
"role": "user",
"content": "List 5 popular cookie recipes."
}
]
completion(
model="gemini/gemini-1.5-pro",
messages=messages,
response_format={"type": "json_object"} # 👈 KEY CHANGE
)
print(json.loads(completion.choices[0].message.content))
- Add model to config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start Proxy
$ litellm --config /path/to/config.yaml
- Make Request!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object"}
}
'
Sample Usage
import os
import litellm
from dotenv import load_dotenv
# Load the environment variables from .env file
load_dotenv()
os.environ["GEMINI_API_KEY"] = os.getenv('GEMINI_API_KEY')
prompt = 'Describe the image in a few sentences.'
# Note: You can pass here the URL or Path of image directly.
image_url = 'https://storage.googleapis.com/github-repo/img/gemini/intro/landmark3.jpg'
# Create the messages payload according to the documentation
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
{
"type": "image_url",
"image_url": {"url": image_url}
}
]
}
]
# Make the API call to Gemini model
response = litellm.completion(
model="gemini/gemini-pro-vision",
messages=messages,
)
# Extract the response content
content = response.get('choices', [{}])[0].get('message', {}).get('content')
# Print the result
print(content)
Usage - PDF / Videos / etc. Files
Inline Data (e.g. audio stream)
LiteLLM follows the OpenAI format and accepts sending inline data as an encoded base64 string.
The format to follow is
data:<mime_type>;base64,<encoded_data>
LITELLM CALL
import litellm
from pathlib import Path
import base64
import os
os.environ["GEMINI_API_KEY"] = ""
litellm.set_verbose = True # 👈 See Raw call
audio_bytes = Path("speech_vertex.mp3").read_bytes()
encoded_data = base64.b64encode(audio_bytes).decode("utf-8")
print("Audio Bytes = {}".format(audio_bytes))
model = "gemini/gemini-1.5-flash"
response = litellm.completion(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please summarize the audio."},
{
"type": "file",
"file": {
"file_data": "data:audio/mp3;base64,{}".format(encoded_data), # 👈 SET MIME_TYPE + DATA
}
},
],
}
],
)
Equivalent GOOGLE API CALL
# Initialize a Gemini model appropriate for your use case.
model = genai.GenerativeModel('models/gemini-1.5-flash')
# Create the prompt.
prompt = "Please summarize the audio."
# Load the samplesmall.mp3 file into a Python Blob object containing the audio
# file's bytes and then pass the prompt and the audio to Gemini.
response = model.generate_content([
prompt,
{
"mime_type": "audio/mp3",
"data": pathlib.Path('samplesmall.mp3').read_bytes()
}
])
# Output Gemini's response to the prompt and the inline audio.
print(response.text)
https:// file
import litellm
import os
os.environ["GEMINI_API_KEY"] = ""
litellm.set_verbose = True # 👈 See Raw call
model = "gemini/gemini-1.5-flash"
response = litellm.completion(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please summarize the file."},
{
"type": "file",
"file": {
"file_id": "https://storage...", # 👈 SET THE IMG URL
"format": "application/pdf" # OPTIONAL
}
},
],
}
],
)
gs:// file
import litellm
import os
os.environ["GEMINI_API_KEY"] = ""
litellm.set_verbose = True # 👈 See Raw call
model = "gemini/gemini-1.5-flash"
response = litellm.completion(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Please summarize the file."},
{
"type": "file",
"file": {
"file_id": "gs://storage...", # 👈 SET THE IMG URL
"format": "application/pdf" # OPTIONAL
}
},
],
}
],
)
Chat Models
We support ALL Gemini models, just set model=gemini/<any-model-on-gemini> as a prefix when sending litellm requests
| Model Name | Function Call | Required OS Variables |
|---|---|---|
| gemini-pro | completion(model='gemini/gemini-pro', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-1.5-pro-latest | completion(model='gemini/gemini-1.5-pro-latest', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-2.0-flash | completion(model='gemini/gemini-2.0-flash', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-2.0-flash-exp | completion(model='gemini/gemini-2.0-flash-exp', messages) | os.environ['GEMINI_API_KEY'] |
| gemini-2.0-flash-lite-preview-02-05 | completion(model='gemini/gemini-2.0-flash-lite-preview-02-05', messages) | os.environ['GEMINI_API_KEY'] |
Context Caching
Use Google AI Studio context caching is supported by
{
{
"role": "system",
"content": ...,
"cache_control": {"type": "ephemeral"} # 👈 KEY CHANGE
},
...
}
in your message content block.
Architecture Diagram
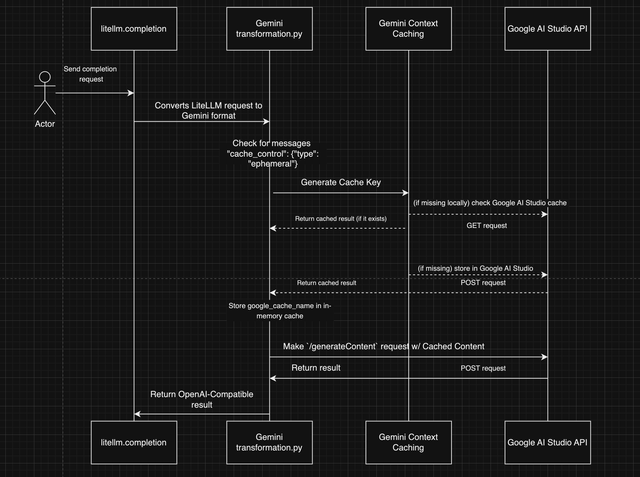
Notes:
Gemini Context Caching only allows 1 block of continuous messages to be cached.
If multiple non-continuous blocks contain
cache_control- the first continuous block will be used. (sent to/cachedContentin the Gemini format)
- The raw request to Gemini's
/generateContentendpoint looks like this:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-001:generateContent?key=$GOOGLE_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"contents": [
{
"parts":[{
"text": "Please summarize this transcript"
}],
"role": "user"
},
],
"cachedContent": "'$CACHE_NAME'"
}'
Example Usage
- SDK
- PROXY
from litellm import completion
for _ in range(2):
resp = completion(
model="gemini/gemini-1.5-pro",
messages=[
# System Message
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {"type": "ephemeral"}, # 👈 KEY CHANGE
}
],
},
# marked for caching with the cache_control parameter, so that this checkpoint can read from the previous cache.
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are the key terms and conditions in this agreement?",
"cache_control": {"type": "ephemeral"},
}
],
}]
)
print(resp.usage) # 👈 2nd usage block will be less, since cached tokens used
- Setup config.yaml
model_list:
- model_name: gemini-1.5-pro
litellm_params:
model: gemini/gemini-1.5-pro
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Test it!
See Langchain, OpenAI JS, Llamaindex, etc. examples
- Curl
- OpenAI Python SDK
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gemini-1.5-pro",
"messages": [
# System Message
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {"type": "ephemeral"}, # 👈 KEY CHANGE
}
],
},
# marked for caching with the cache_control parameter, so that this checkpoint can read from the previous cache.
{
"role": "user",
"content": [
{
"type": "text",
"text": "What are the key terms and conditions in this agreement?",
"cache_control": {"type": "ephemeral"},
}
],
}],
}'
import openai
client = openai.AsyncOpenAI(
api_key="anything", # litellm proxy api key
base_url="http://0.0.0.0:4000" # litellm proxy base url
)
response = await client.chat.completions.create(
model="gemini-1.5-pro",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "Here is the full text of a complex legal agreement" * 4000,
"cache_control": {"type": "ephemeral"}, # 👈 KEY CHANGE
}
],
},
{
"role": "user",
"content": "what are the key terms and conditions in this agreement?",
},
]
)
Image Generation
- SDK
- PROXY
from litellm import completion
response = completion(
model="gemini/gemini-2.0-flash-exp-image-generation",
messages=[{"role": "user", "content": "Generate an image of a cat"}],
modalities=["image", "text"],
)
assert response.choices[0].message.content is not None # "data:image/png;base64,e4rr.."
- Setup config.yaml
model_list:
- model_name: gemini-2.0-flash-exp-image-generation
litellm_params:
model: gemini/gemini-2.0-flash-exp-image-generation
api_key: os.environ/GEMINI_API_KEY
- Start proxy
litellm --config /path/to/config.yaml
- Test it!
curl -L -X POST 'http://localhost:4000/v1/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "gemini-2.0-flash-exp-image-generation",
"messages": [{"role": "user", "content": "Generate an image of a cat"}],
"modalities": ["image", "text"]
}'