

Key Highlights
- SCIM Integration: Enables identity providers (Okta, Azure AD, OneLogin, etc.) to automate user and team (group) provisioning, updates, and deprovisioning
- Team and Tag based usage tracking: You can now see usage and spend by team and tag at 1M+ spend logs.
- Unified Responses API: Support for calling Anthropic, Gemini, Groq, etc. via OpenAI's new Responses API.
Let's dive in.
SCIM Integration

This release adds SCIM support to LiteLLM. This allows your SSO provider (Okta, Azure AD, etc) to automatically create/delete users, teams, and memberships on LiteLLM. This means that when you remove a team on your SSO provider, your SSO provider will automatically delete the corresponding team on LiteLLM.
Team and Tag based usage tracking
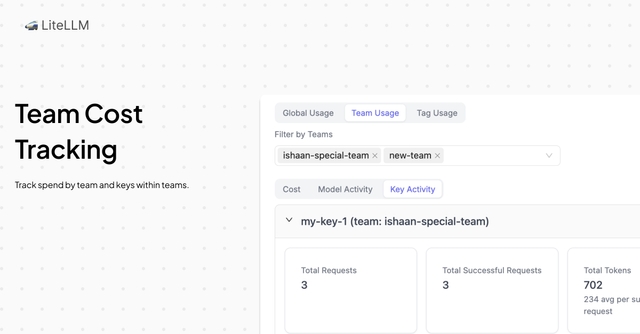
This release improves team and tag based usage tracking at 1m+ spend logs, making it easy to monitor your LLM API Spend in production. This covers:
- View daily spend by teams + tags
- View usage / spend by key, within teams
- View spend by multiple tags
- Allow internal users to view spend of teams they're a member of
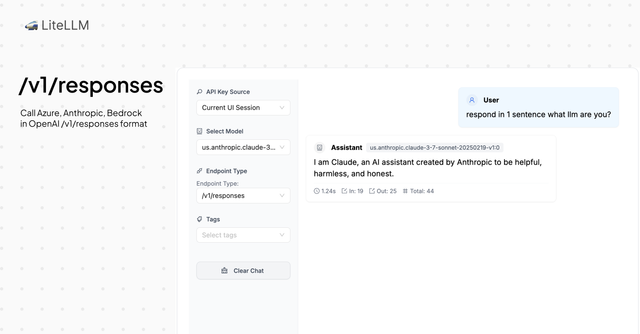
Unified Responses API
This release allows you to call Azure OpenAI, Anthropic, AWS Bedrock, and Google Vertex AI models via the POST /v1/responses endpoint on LiteLLM. This means you can now use popular tools like OpenAI Codex with your own models.
New Models / Updated Models
- OpenAI
- gpt-4.1, gpt-4.1-mini, gpt-4.1-nano, o3, o3-mini, o4-mini pricing - Get Started, PR
- o4 - correctly map o4 to openai o_series model
- Azure AI
- Phi-4 output cost per token fix - PR
- Responses API support Get Started,PR
- Anthropic
- redacted message thinking support - Get Started,PR
- Cohere
/v2/chatPassthrough endpoint support w/ cost tracking - Get Started, PR
- Azure
- Support azure tenant_id/client_id env vars - Get Started, PR
- Fix response_format check for 2025+ api versions - PR
- Add gpt-4.1, gpt-4.1-mini, gpt-4.1-nano, o3, o3-mini, o4-mini pricing
- VLLM
- Files - Support 'file' message type for VLLM video url's - Get Started, PR
- Passthrough - new
/vllm/passthrough endpoint support Get Started, PR
- Mistral
- new
/mistralpassthrough endpoint support Get Started, PR
- new
- AWS
- New mapped bedrock regions - PR
- VertexAI / Google AI Studio
- Gemini - Response format - Retain schema field ordering for google gemini and vertex by specifying propertyOrdering - Get Started, PR
- Gemini-2.5-flash - return reasoning content Google AI Studio, Vertex AI
- Gemini-2.5-flash - pricing + model information PR
- Passthrough - new
/vertex_ai/discoveryroute - enables calling AgentBuilder API routes Get Started, PR
- Fireworks AI
- return tool calling responses in
tool_callsfield (fireworks incorrectly returns this as a json str in content) PR
- return tool calling responses in
- Triton
- Remove fixed remove bad_words / stop words from
/generatecall - Get Started, PR
- Remove fixed remove bad_words / stop words from
- Other
- Support for all litellm providers on Responses API (works with Codex) - Get Started, PR
- Fix combining multiple tool calls in streaming response - Get Started, PR
Spend Tracking Improvements
- Cost Control - inject cache control points in prompt for cost reduction Get Started, PR
- Spend Tags - spend tags in headers - support x-litellm-tags even if tag based routing not enabled Get Started, PR
- Gemini-2.5-flash - support cost calculation for reasoning tokens PR
Management Endpoints / UI
Users
- Show created_at and updated_at on users page - PR
Virtual Keys
- Filter by key alias - https://github.com/BerriAI/litellm/pull/10085
Usage Tab
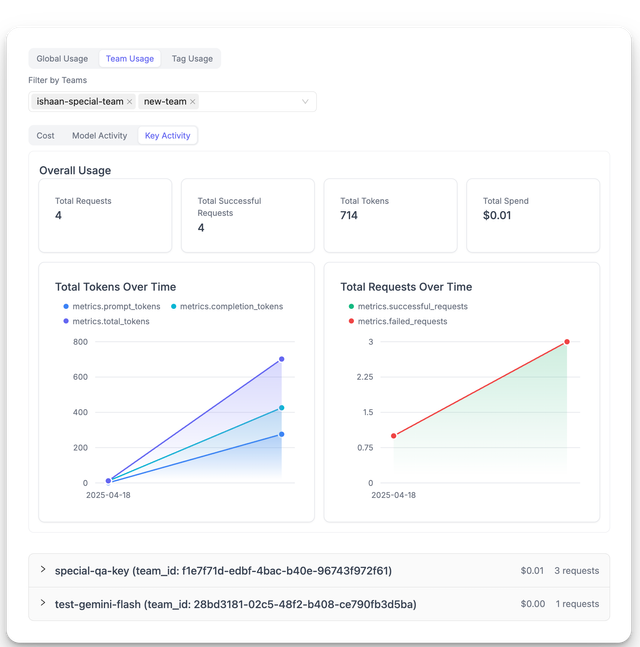
Team based usage
New
LiteLLM_DailyTeamSpendTable for aggregate team based usage logging - PRNew Team based usage dashboard + new
/team/daily/activityAPI - PRReturn team alias on /team/daily/activity API - PR
allow internal user view spend for teams they belong to - PR
allow viewing top keys by team - PR
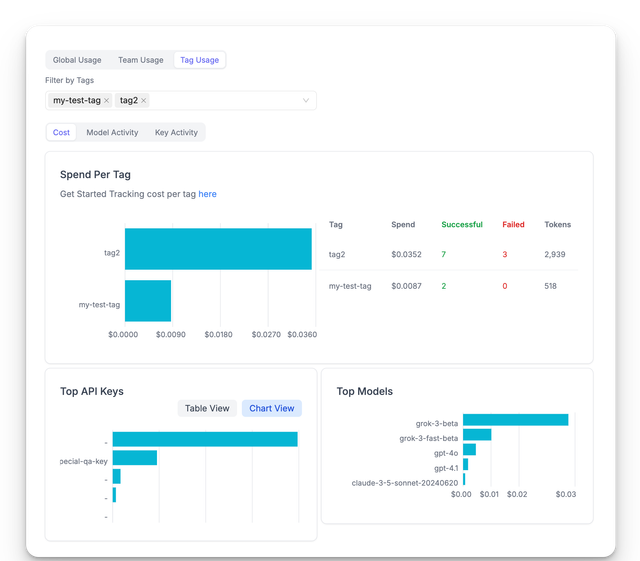
Tag Based Usage
Track prompt caching metrics in daily user, team, tag tables - PR
Show usage by key (on all up, team, and tag usage dashboards) - PR
swap old usage with new usage tab
Models
- Make columns resizable/hideable - PR
API Playground
- Allow internal user to call api playground - PR
SCIM
- Add LiteLLM SCIM Integration for Team and User management - Get Started, PR
Logging / Guardrail Integrations
- GCS
- Fix gcs pub sub logging with env var GCS_PROJECT_ID - Get Started, PR
- AIM
- Add litellm call id passing to Aim guardrails on pre and post-hooks calls - Get Started, PR
- Azure blob storage
- Ensure logging works in high throughput scenarios - Get Started, PR
General Proxy Improvements
- Support setting
litellm.modify_paramsvia env var PR - Model Discovery - Check provider’s
/modelsendpoints when calling proxy’s/v1/modelsendpoint - Get Started, PR /utils/token_counter- fix retrieving custom tokenizer for db models - Get Started, PR- Prisma migrate - handle existing columns in db table - PR